Building TARA: From Dashcam to Investment Decision in 5 Minutes
Road appraisal in Africa is broken. The process is too expensive, too slow, and too dependent on scarce specialists to work at the scale the continent needs.
Africa needs 130–170 billion per year in infrastructure investment (the African Development Bank estimates $181–221 billion over 2023-2030). What’s less discussed is why the money doesn’t flow: about 80% of infrastructure projects fail at the feasibility and planning stage. The bottleneck is appraisal. Before anyone invests in a road, it needs an economic assessment. Is this road worth the money?
The standard process: a survey team drives the road with specialised equipment. Data gets compiled into spreadsheets. A transport economist runs the numbers. Someone formats a report. The whole cycle takes about 5 weeks and costs thousands of dollars per road. And that’s assuming you have the data. Collecting condition data across a road network requires expensive automated survey vehicles fitted with laser profilers and cameras. Most road agencies can only afford to survey a fraction of their network each year. The rest goes unmeasured. Investment decisions for those roads get made on incomplete data or no data at all.
Most roads in Africa never get appraised at all. The process is too expensive for the roads that need it most: secondary and rural roads serving communities with no alternative routes.
TARA changes that. Upload dashcam footage with GPS data, and get a complete economic appraisal. Condition assessment, cost-benefit analysis, equity scoring, and a professional PDF report. Five minutes. About $6 in API costs.
I built it in 6 days for the Anthropic Built with Claude Hackathon. It won the Keep Thinking Prize, selected from approximately 500 submissions.
This is the story of the workflow that made it possible. What I brought, what Claude brought, and what the combination produced.
Hackathon Demo Video
What TARA Does
TARA (Transport Appraisal & Risk Analysis) is a 7-step wizard that takes a road from raw dashcam footage to a complete investment decision.
Step 1: Road Selection. In the hackathon version, road selection was manual. I used dashcam footage with GPX data from open GPS files (mytrax). The dropdown of 738 Ugandan roads from a local OpenStreetMap database is being built for the next version.
Step 2: Condition Assessment. Upload dashcam footage. A phone mount, a GoPro, anything. I used a $56 Yesido dashcam mount on an iPhone. TARA extracts frames and sends them to Claude Vision, which scores each frame for surface type, distress severity against engineering standards (TMH12 for unsealed roads, ASTM D6433 for paved), and roadside environment. It also identifies pedestrians, cyclists, and schoolchildren, because road users matter, not just road surfaces.
The frames become a condition map: extract, GPS match, score, aggregate, GeoJSON.
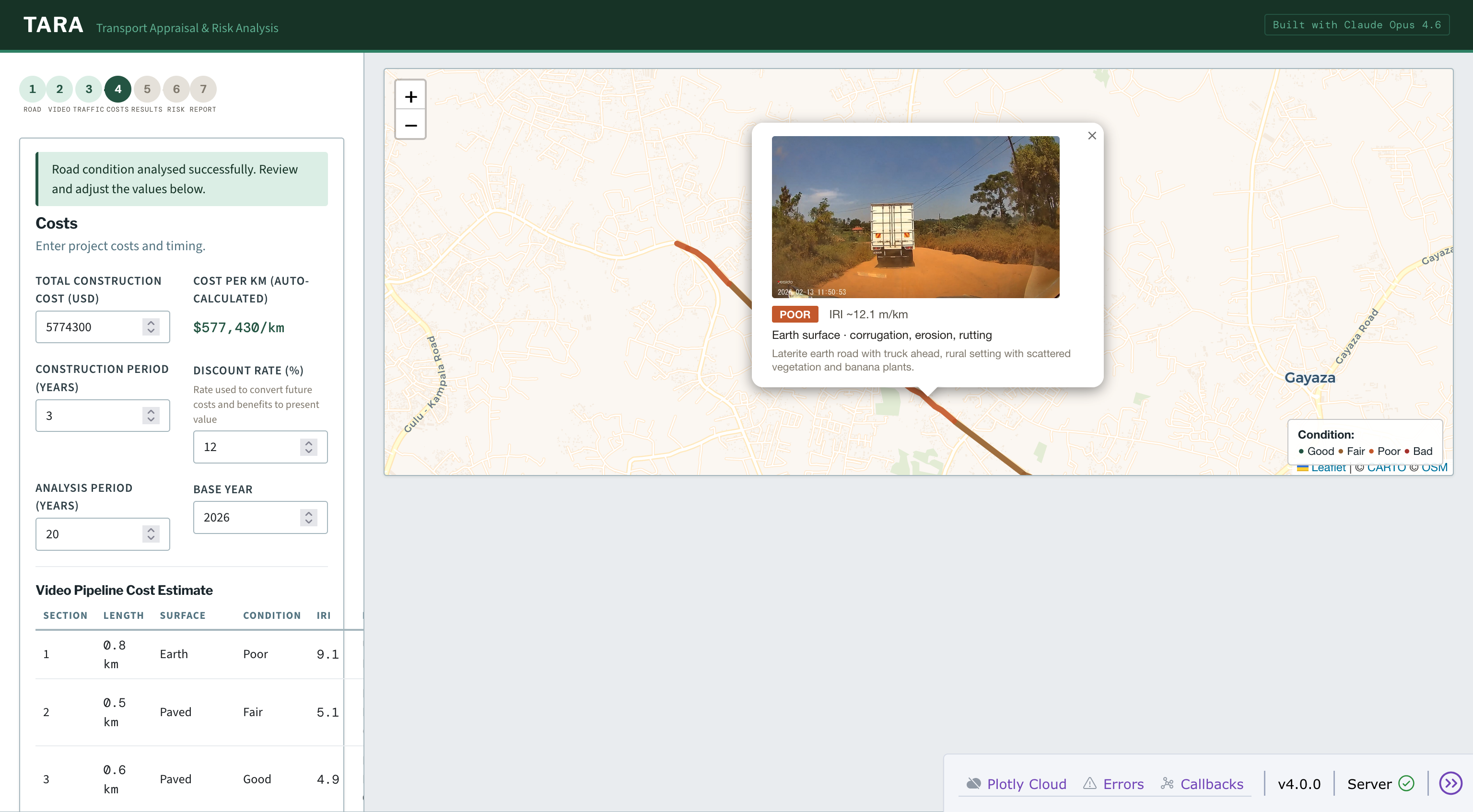 Screenshot showing road sections scored by Claude Vision and Video Costs estimates
Screenshot showing road sections scored by Claude Vision and Video Costs estimates
Step 3: Traffic Data. Input traffic volumes, or use TARA’s defaults based on road classification.
Step 4: Cost Calculation. TARA recommends interventions based on the condition assessment and calculates Uganda-calibrated costs per section.
Step 5: Economic Analysis. The CBA engine calculates vehicle operating cost savings, value of time savings, and accident reduction benefits. Out comes NPV, EIRR, and BCR, the three numbers that determine whether a road gets funded, with a cumulative NPV curve.
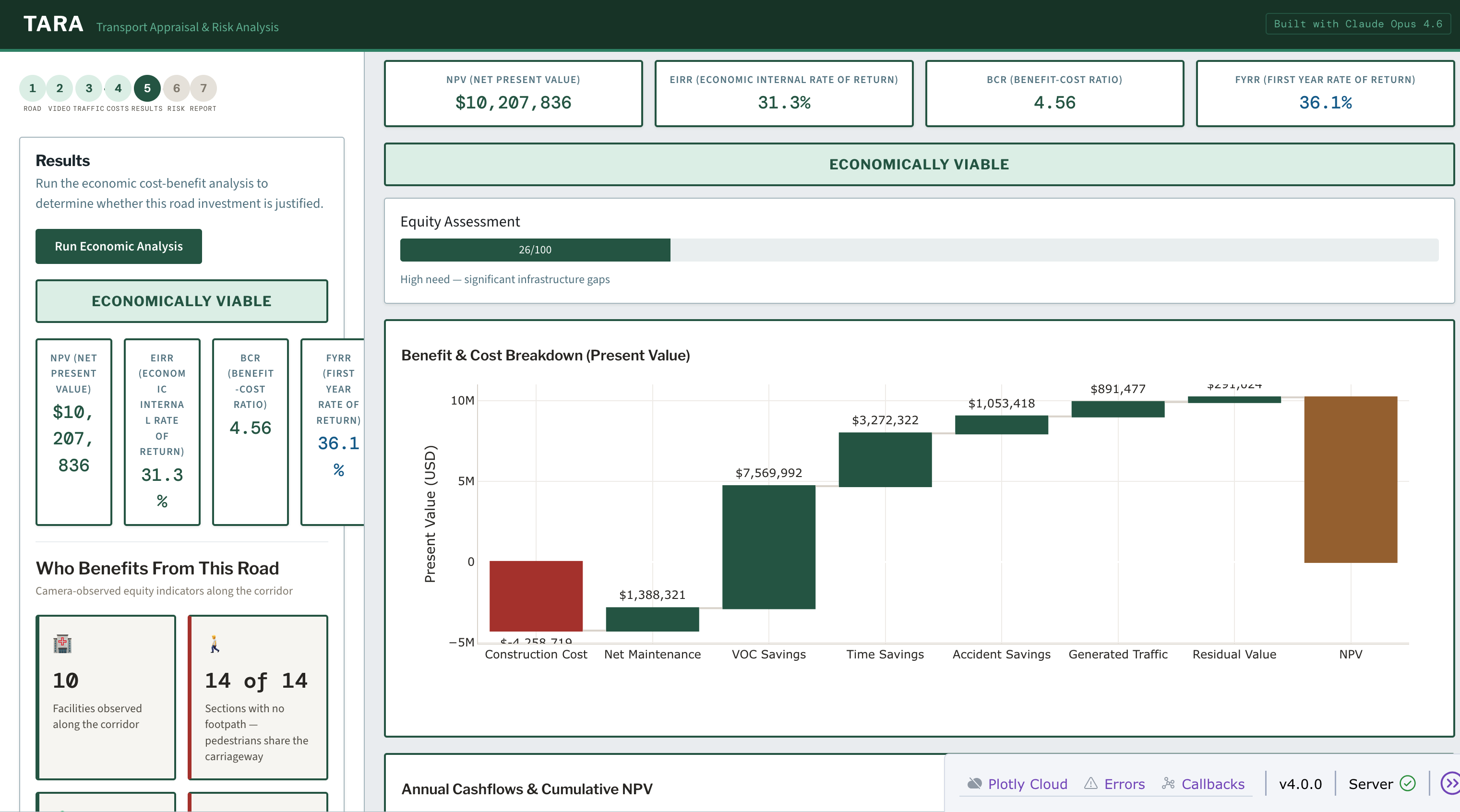 Screenshot CBA results
Screenshot CBA results
Step 6: Equity Assessment. This is where TARA does something most appraisal tools skip. Claude Vision scores pavement condition but also sees the people using the road: pedestrians, boda bodas, cyclists, schoolchildren. It identifies schools, markets, religious institutions, and other facilities visible in the frames. From this, it generates a rough equity score for each section based on what was actually observed during the drive-through. Claude then writes a narrative interpreting what this means for the communities along the road. In the hackathon version, this was vision-based only, demonstrating the possibilities. The next version will integrate external population data (UBOS) and facility counts (OpenStreetMap) for a more robust score.
A road with an EIRR of 15% might seem marginal in pure economic terms. But if it’s the only route connecting 120,000 people to the nearest hospital, and 68% of them live below the poverty line, the equity-weighted NPV tells a different story.
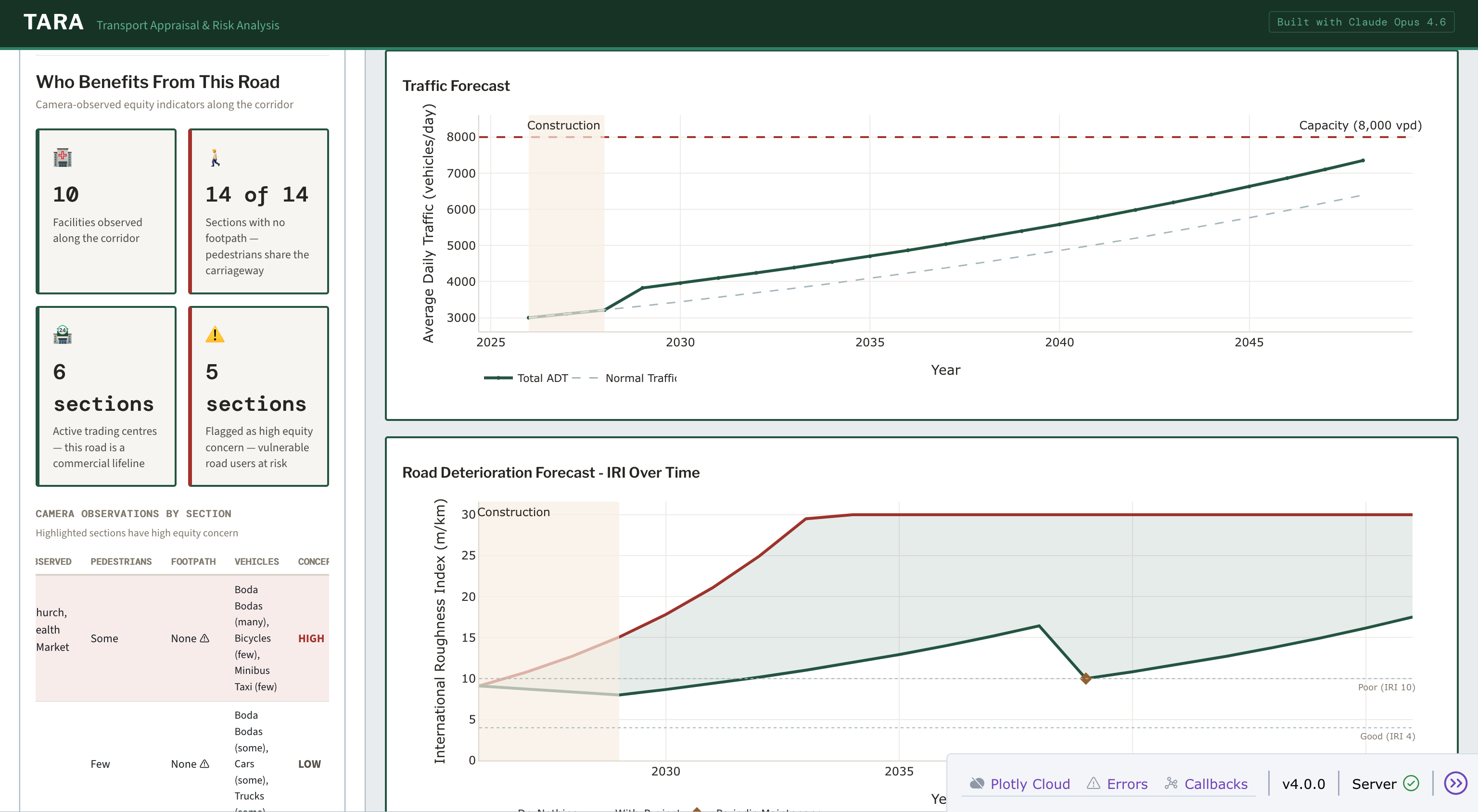 Screenshot showing the equity dashboard
Screenshot showing the equity dashboard
Step 7: Sensitivity Analysis. Claude identifies which assumptions are most uncertain for this specific road, not a generic ±20% on everything. A tornado diagram shows which variables would flip the investment decision.
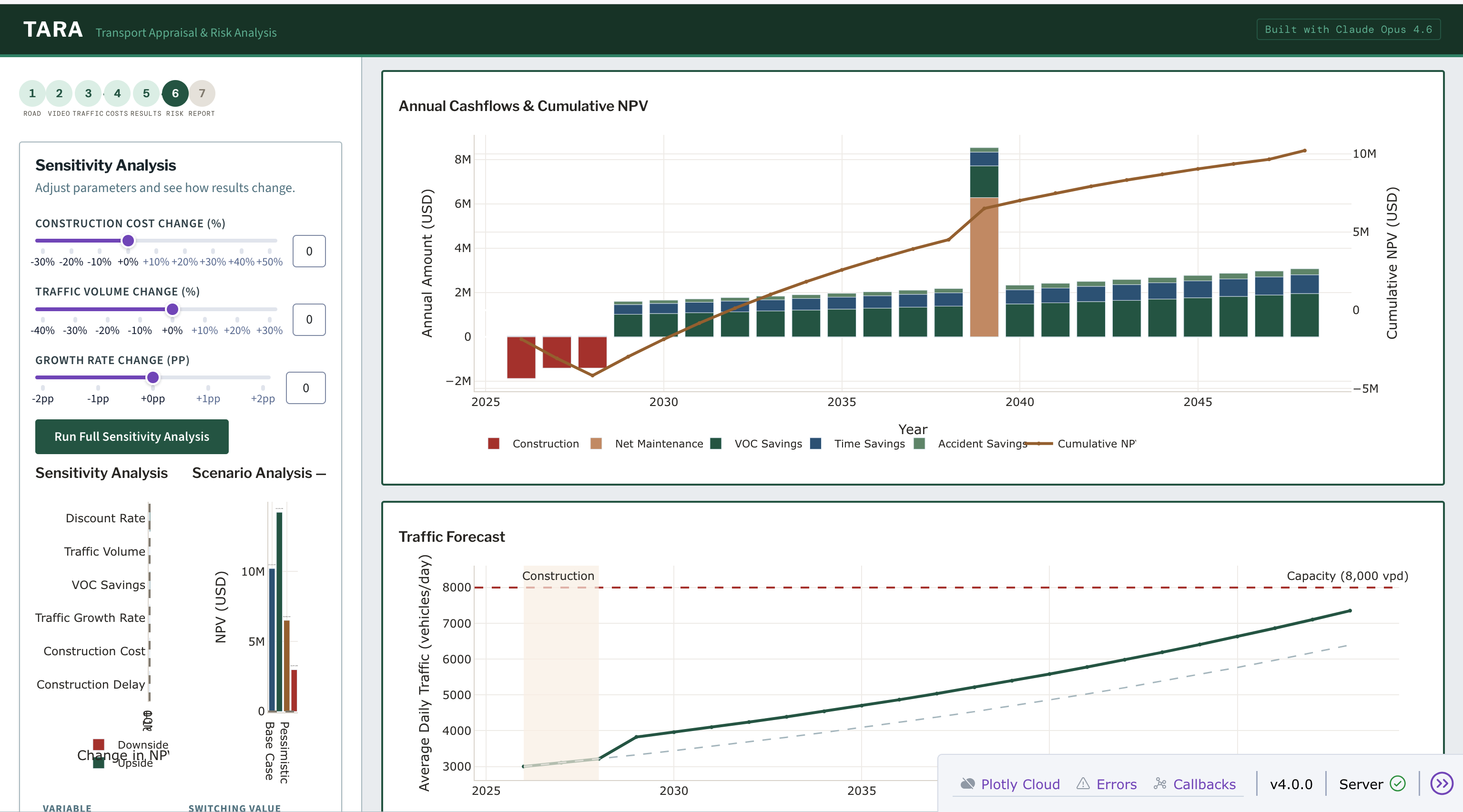 Screenshot showing Sensitivity Analysis
Screenshot showing Sensitivity Analysis
One click generates a professional PDF report. Total cost: approximately $6 in API calls.
| Traditional approach | With TARA | |
|---|---|---|
| Time per road | ~5 weeks | ~5 minutes |
| Cost per road | Thousands of $ | ~$6 |
| Data collection | Specialised survey vehicles (expensive, limited coverage) | Any dashcam or phone ($56 mount) |
| Analysis | HDM-4 or similar (detailed, resource-intensive) | Rapid screening to identify roads worth detailed analysis |
| Expertise needed | Transport economist + survey team | Transport economist (Domain expert) + Claude |
| Equity assessment | Usually skipped | Built in |
| Report | Manual formatting | Auto-generated PDF |
| Network coverage | Fraction of network per year | Entire network feasible |
TARA is not a replacement for HDM-4 or detailed project-level appraisal. It is a screening tool. When a road agency has thousands of roads and limited budget, TARA can rapidly identify which roads have the strongest economic and social case for investment. Those roads then go through the detailed analysis. The transport economists who currently spend weeks on individual appraisals can work on more roads and do deeper analysis on the ones that matter most.
Why This Matters
TARA is a hackathon project. The problem behind it is decades old.
In 2018, I was part of the team developing the plan for Uganda’s Third National Development Plan. We needed to rank roads for upgrading across the national network. Fixing every road that needed development work would have cost UGX 32 trillion, roughly $8.6 billion. The annual budget for roads was about UGX 4 trillion per year, approximately $1.1 billion, covering both development and maintenance. Not all of that could go to new construction. We needed a way to put limited money where it would have the most impact.
That requires data. You need to know the condition of every road, the traffic it carries, the communities it serves. Then you can compare roads and prioritise.
The tool we had was an automated survey vehicle fitted with laser profilers and high-definition cameras. These vehicles cost hundreds of thousands of dollars. We could not run it on the whole network of 21,000km. We kept it for the 6,000 most important kilometres, and it was difficult to get it to complete even those in a year. The remaining 15,000km of the network went unmeasured. Decisions about those roads were made with incomplete data or no data at all.
This is where fast, low-cost appraisal changes the equation. A dashcam on any vehicle driving a road can collect condition data. Claude Vision scores it against engineering standards. The CBA engine calculates whether the investment makes economic sense. The equity module asks who benefits. A phone mount costs $56. The API cost is $6 per road.
Scale that across a network and you can do something that was previously impossible: collect condition data and observe actual road usage across all 21,000km, not just the 6,000km you can afford to survey with specialist equipment. Decisions get made based on actual condition and the traffic and activity seen during the drive-through. Not estimates. Not last year’s survey of a different road. The real state of this road, this year.
That’s why I think TARA’s capabilities are best used as a screening tool for network-level road management with data instead of educated guesswork.
How I Got Here
I’m a transport engineer who writes Python.
My Master’s thesis involved automating HDMSentry a simplified entry system for HDM-4. After that, I built automated traffic analysis sheets for the critical oil road projects in Uganda in 2017 and continued using python scripts to handle the boring repetitive parts of my job like preparing HDM-4 inputs, regular reports and clerical procurement tasks Useful work, but it was automation of my own workflow. The scripts made me faster. I couldn’t really build and package anything for anyone else.
The shift came from the fast.ai course and George Polya’s How to Solve It: understand the problem, make a plan, carry out the plan, look back. Answer.AI’s SolveIt method adapted this for working with AI. They recommend small batches, rapid iteration with AI as a thinking partner and not a prompt once and forget system. I applied this to Zidi, a Uganda fixed income market platform built in FastHTML. Zidi was proof that a domain expert, using AI as a collaborative partner, could ship a real product. But it was still within my programming ability.
When Anthropic announced the Claude Code Hackathon I decided to see how far this method can actually go. Could a domain expert, working with AI as a full engineering team, build something in 6 days that would normally take months and multiple specialists?
The test was TARA. The answer was much further than I expected.
The Workflow
The most important thing I built was a workflow, not code. It was not a decision I thought about before but just came to with trial and error.
Three parallel channels ran simultaneously throughout the build:
Channel 1: Strategy Chat (Claude.ai). High-level decisions, architecture changes, problem-solving. No code in this channel. This chat held the hackathon rules, my domain documents (UNRA HDM-4 Calibration study, Highway-1 Excel model, MoFPED guidelines, equity research from a course from the Oxford Transport Studies Unit on equity and justice in transport I had taken last year, and every architectural decision.
Channel 2: Feature Chats (Claude.ai). One dedicated chat per feature. Each produced a detailed implementation prompt for Claude Code. The video chat didn’t know about equity. The CBA chat didn’t know about the UI. Each stayed focused on one problem. The strategy and feature chats were contained in one project on claude.ai. Claude is able to use context from other chats within the same project but I find you have to explicitly ask it to look. It is not able to reference chats outside the project you are working in.
Channel 3: Claude Code (CLI). This is the builder. It lives in the Command Line Interface (CLI) It reads the codebase, runs the code, tests it, iterates. It spawned sub-agents for parallel work on separate files. I tried using claude code in the claude app offered for macOs but found it works better when you access it from the command line . This is for the version then. Claude code has changed a lot since February. 6 weeks in this AI world are like months in years before.
Strategy and execution need different context windows. Mixing them overflows both. I’d watched that degradation happen in long conversations during the Zidi build.
Teach before you build. The most productive time was the beginning, when I uploaded everything I knew to Claude: my Obsidian notes i had taken on what i thought an automated appraisal system should look like, reference documents, the hackathon rules. Before any code was written, Claude had helped me decide between trying to develop a broad appraisal platform and a focused tool. I ended up choosing the focused approach based on recommendations from claude. Do not take the first solution offered. Push back and ask the model what other options are possible. The discussion helped me rank easy wins, features I would like to have and moonshot features based on their demo impact versus build effort. That framework held for the entire build and guided how I spent my time.
The FastHTML pivot. I had planned to use FastHTML, the framework I’d used for Zidi. Claude recommended Dash for better integration with the map components. I’d never used Dash before. But Dash is written in Python, and I’d been writing Python for years. That familiarity with the language meant I could read what Claude was building, understand the logic even when I hadn’t written it, and catch problems.
Sub-agent architecture. For the video pipeline, I described to Claude what each component needed to do. Claude drafted the orchestrator prompt in the strategy chat. Five sub-agents, each working on its own file:
Sub-Agent 1: Frame Extraction (video_frames.py)
Sub-Agent 2: GPS Utilities (gps_utils.py)
Sub-Agent 3: Vision Assessment (vision_assess.py)
Sub-Agent 4: Map & Narrative (video_map.py)
Sub-Agent 5: Pipeline Orchestrator (video_pipeline.py)I reviewed it, adjusted the domain-specific parts (the scoring rubric against TMH12 standards, the severity classifications an engineer would expect), and handed it to Claude Code. It spawned sub-agents, built all five files, tested with real dashcam footage from the [Kasangati-Matugga road](Kyaliwajjala–Kira–Kasangati–Matugga Road - Wikipedia) in Uganda, and came back with a working pipeline in about 90 minutes.
My job was to know what correct output looked like. Claude generated the code. I checked whether the condition scores matched field standards and whether the outputs were economically sensible. That review is the product.
The Equity Question
With the core pipeline working (condition assessment, CBA, sensitivity analysis), I stopped and thought about what I was actually building.
I focused on building a system for rudimentary equity analysis. I focused on getting TARA to see the vulnerable road users like pedestrians, cyclists, schoolchildren, and market traders. The result was a vision prompt which captures roadside environment and non-motorised transport provision alongside pavement condition. It sees the humans who use the road.
In the hackathon version, equity scoring is entirely vision-based. Claude reads each frame and identifies not just road condition but road users and roadside activity: pedestrians, boda bodas, cyclists, schools, markets, places of worship. It uses what it sees to generate a rough equity score for each section. Claude then writes a narrative interpreting what this means for the communities along the road. The next version will layer in external data (UBOS population, OpenStreetMap facility counts) for a more robust assessment, but the vision-based approach already demonstrates what’s possible.
The equity dimension was designed in because infrastructure decisions shape who has access to healthcare, education, and economic opportunity. If there are 120,000 people with 68% below the poverty line and only one road to the nearest hospital. It is important the appraisal tool measures that, so that decision-makers see it and not just a dry project Internal rate of Return (IRR) or Net Present Value (NPV) number.
Under the Hood
The hybrid model approach. Each vision frame costs about 1,229 tokens. With 20+ frames per survey, costs add up. The Sonnet model scores each dashcam frame: surface type, distress severity, pedestrians. I chose that model because it is fast, cheap, and accurate enough for per-frame classification. Opus interprets the overall condition narrative, reasons about sensitivity analysis, and writes the equity assessment. Matching the model to the task kept costs at about $6 per appraisal. Using Opus for everything would have cost 10x more with marginal improvement on classification.
Automating the build process
The first night. I was literally awake until morning approving Claude Code commands. Every time it needed to run something, a prompt appeared on my screen. python app.py. Approve. pip install dash-leaflet. Approve. cat config.json. Approve. During quiet phases it was every few minutes. During intense build sprints where Claude Code was iterating, testing, fixing, and testing again, the approvals came in bursts. I was sitting there at 3am hitting yes to safe commands instead of thinking about whether the CBA engine was calculating vehicle operating costs correctly.
That kind of baby sitting throws many people off and they stop building. However it is possible to automate the process using Claude Code hooks. No one wants to run claude code on their main laptop in YoLo mode with with --dangerously-skip-permissions thats just reckless.
Claude Code hooks changed everything. I configured a settings.json that removed the friction of constant approvals. The config has four layers:
Layer 1: Session start. Every time Claude Code starts, a hook runs git status, shows the last 5 commits, and pulls unchecked items from CLAUDE.md. The agent starts every session knowing where it left off.
"SessionStart": [{
"hooks": [{
"type": "command",
"command": "echo '=== GIT STATUS ===' && git status --short && echo '=== RECENT COMMITS ===' && git log --oneline -5 && echo '=== TODO ===' && grep -n '\\- \\[ \\]' CLAUDE.md 2>/dev/null"
}]
}]Layer 2: Auto-approve safe commands. File reads, Python runs, package installs, git status, directory listing. 30+ matchers covering everything that can’t destroy work. These were the commands I was approving at 3am.
{"matcher": "Bash(python *)", "hooks": [{"type": "command", "command": "echo '{\"decision\": \"approve\"}'"}]},
{"matcher": "Bash(pip install*)", "hooks": [{"type": "command", "command": "echo '{\"decision\": \"approve\"}'"}]},
{"matcher": "Bash(cat *)", "hooks": [{"type": "command", "command": "echo '{\"decision\": \"approve\"}'"}]},
{"matcher": "Write", "hooks": [{"type": "command", "command": "echo '{\"decision\": \"approve\"}'"}]}Layer 3: Block dangerous commands. Recursive deletes, force pushes, branch deletions, hard resets. Anything that could destroy work gets blocked before Claude Code can run it.
"PreToolUse": [{
"matcher": "Bash",
"hooks": [{
"type": "command",
"command": "...case \"$CMD\" in *rm\\ -rf*|*git\\ push*|*git\\ reset\\ --hard*) echo '{\"decision\": \"block\", \"reason\": \"Blocked: destructive operation\"}' ;; esac"
}]
}]Layer 4: Self-review on every stop. When Claude Code finishes a task, a prompt fires: does the code run? Did you test it? Are there obvious bugs? If issues remain, keep fixing. A builder-critic loop. The agent checks its own work before surfacing it. A separate hook does the same for sub-agents, evaluating their output for completeness and integration before accepting it.
"Stop": [{
"hooks": [{
"type": "prompt",
"prompt": "Before finishing, critically review the work you just completed: 1. Does the code run without errors? 2. Are there obvious bugs? 3. Does it match what was asked for? If ANY issues remain, respond 'continue' and fix them."
}]
}]After configuring these hooks, the workflow improved significantly. I wasn’t approving safe commands at 3am any more. Claude Code could run scripts, test, catch obvious errors through the self-review hook, and flag results for my attention. But hooks alone don’t make Claude Code fully autonomous. They remove the friction of constant approvals. The domain review, the architectural decisions, the judgment calls about whether the output is correct, those still need a human in the loop. Hooks let me focus on that work instead of babysitting bash commands.
For builders: configure your hooks before you start building. The time I spent awake on Night 1 approving ls commands was time I should have spent sleeping so I could make better architectural decisions the next morning. Also you do not have to write the JSON in the hooks yourself. Ask claude code to write them. That’s what it is there for.
What I Actually Did
It’s worth being direct about the division of labour. The honest version is more useful to anyone who wants to replicate this.
What I brought: The problem definition: knowing what road appraisal does, where it fails, and what a useful output looks like. Domain calibration: checking whether AI scoring matched engineering standards, whether the CBA outputs were economically sensible, whether the equity framing captured what actually matters to funders. Every judgement call about whether the data was correct. The equity vision: the idea that the tool should ask “who benefits?” came from 10 years of working in African infrastructure, not from any codebase. Data source selection: knowing which Ugandan datasets exist and which are reliable. Quality judgment throughout. My experience as a transport engineer was what I brought to the table.
What Claude brought: The Dash recommendation (I had planned FastHTML). The architecture documents (I described the goal; Claude structured the approach). All the code, approximately 7,000 lines across 16 files. The orchestrator and sub-agent prompts, drafted in the strategy chat, reviewed and adjusted by me. The CBA engine, the equity narrative, the sensitivity reasoning, the executive summary. Debugging: every time something broke, I described the problem and Claude diagnosed it.
What the workflow produced: One transport engineer delivering what would normally require a software developer, a transport economist, and a GIS specialist. The workflow gave AI the domain context to fill those roles under expert supervision.
What Didn’t Work
Large video uploads crashed the browser. Uncompressed dashcam files (95MB each) caused “allocation size overflow” errors. Fix: pre-compress with ffmpeg to 3-5MB, use a dataset dropdown instead of browser upload.
Context overflow in long conversations. The main strategy conversation grew too large after days of work. Fix: compact, start new focused chats for new features, keep the strategy chat for high-level decisions only.
Sub-agent file conflicts. Two sub-agents assigned to files that shared dependencies. When both modified function signatures, integration broke. Fix: one agent per file, orchestrator handles integration. Always.
Lessons for Builders
Your domain knowledge is the thing AI doesn’t have. Claude can write Dash. It cannot calibrate a pavement distress scoring rubric against your country’s standards. It cannot decide that equity should be a first-class output. The irreplaceable input is knowing your field well enough to judge whether the AI’s work is correct.
Teach before you build. The first stage was uploading domain documents and having Claude internalise the problem. Everything after was faster because Claude already understood road appraisal. Whatever your domain, the more context you load upfront, the less correction you’ll do downstream.
Describe the goal; let AI structure the approach. I knew what each component needed to produce. Claude designed how to build it. Domain expert defines the output, AI designs the architecture.
Separate strategy and execution. One chat for decisions, one per feature for specs, Claude Code for building. Mixing them overflows context and degrades results at every level.
Build in tiers. Always have something presentable. Tier 1 was the safety net. Tier 2 was the target. Tier 3 was the stretch. Trying to build everything at once just doesn’t work. Plan out the master strategy and then build in phases. Check every phase as complete before moving to the next one. For actual software and not demos confirming completion includes testing and verifying what the AI has build and that it is maintainable.
Match the model to the task. I used Sonnet for classification and Opus for reasoning. There is the temptation to just throw everything at the best model. That’s just a waste of resources. The lower tier models will do a fantastic job at some of the usual tasks at a fraction of the cost. Don’t use your most expensive model for structured data extraction. Don’t use your cheapest for narrative interpretation.
The question you ask determines what you build. TARA could have been a pure economic calculator. The equity dimension came from pausing and asking what this tool should actually be. That question doesn’t come from any prompt. It comes from knowing why road appraisal matters. Domain expertise is why AI wont take your job. It will just make you more effective in your role.
What’s Next
TARA is open source, MIT licensed. The code is on GitHub.
Validation is first: testing TARA’s Visual Condition Index against professional survey data to calibrate accuracy. Then pilots with road agencies on real decision-making workflows.
The bigger vision: dashcams on public vehicles (buses, delivery trucks) feeding a continuous national road condition monitoring system. A living map of infrastructure health.
If you’re a transport professional, a road agency, or a builder who wants to try TARA on your roads, the tool is free, the methodology is open.
What does this mean for working with AI
TARA is a road appraisal tool. But I believe the pattern that it reveals is universal. Having domain expertise and working with AI can enable us to build effective tools and solutions.
I’m a transport engineer who had some Python, a problem-solving method that worked, and a problem worth solving. The knowledge that made TARA possible was 16 years of understanding how road appraisal works, what the outputs need to contain, and whether the AI’s work was right.
Before the release of Opus 4.6, I could write scripts to automate my own analysis. After that, I could build a tool that other engineers can use.
The collaboration only works because one person in it knows the domain. Claude can generate 7,000 lines of Dash and Python. It cannot look at a Visual Condition Index score and know whether it reflects what a field engineer would find on the ground. That judgment is the thing you bring.
That’s what Mwangaza is about. The AI tools are free and available to everyone. The craft is knowing your domain well enough to supervise what AI builds and building a harness that directs what AI does. If you’re a professional who knows your field but doesn’t have a software team, the tools exist now. Your domain expertise is what they’ve been waiting for.
TARA won the Keep Thinking Prize at the Anthropic Built with Claude global hackathon, February 2026.
How this was written: The ideas, structure, and engineering context are the author’s. AI (Claude) assisted with drafting and editing. All technical details have been verified.
Have feedback or questions? Reply on LinkedIn or email kye@mwangaza.ai.